
You are here
Science Resources: DNA Technologies
Probabilistic Genotyping Systems for Low-Quality and Mixture Forensic Samples
Forensic DNA identification evidence has become a powerful tool for investigations and the authority of DNA evidence has encouraged the collection of DNA samples in any environment. The collection of DNA has become ubiquitous, and collection techniques are more sensitive; these factors have led to more complex mixture samples, where the DNA profile reveals multiple contributors of varying proportion and clarity (Fig. 20).[1]
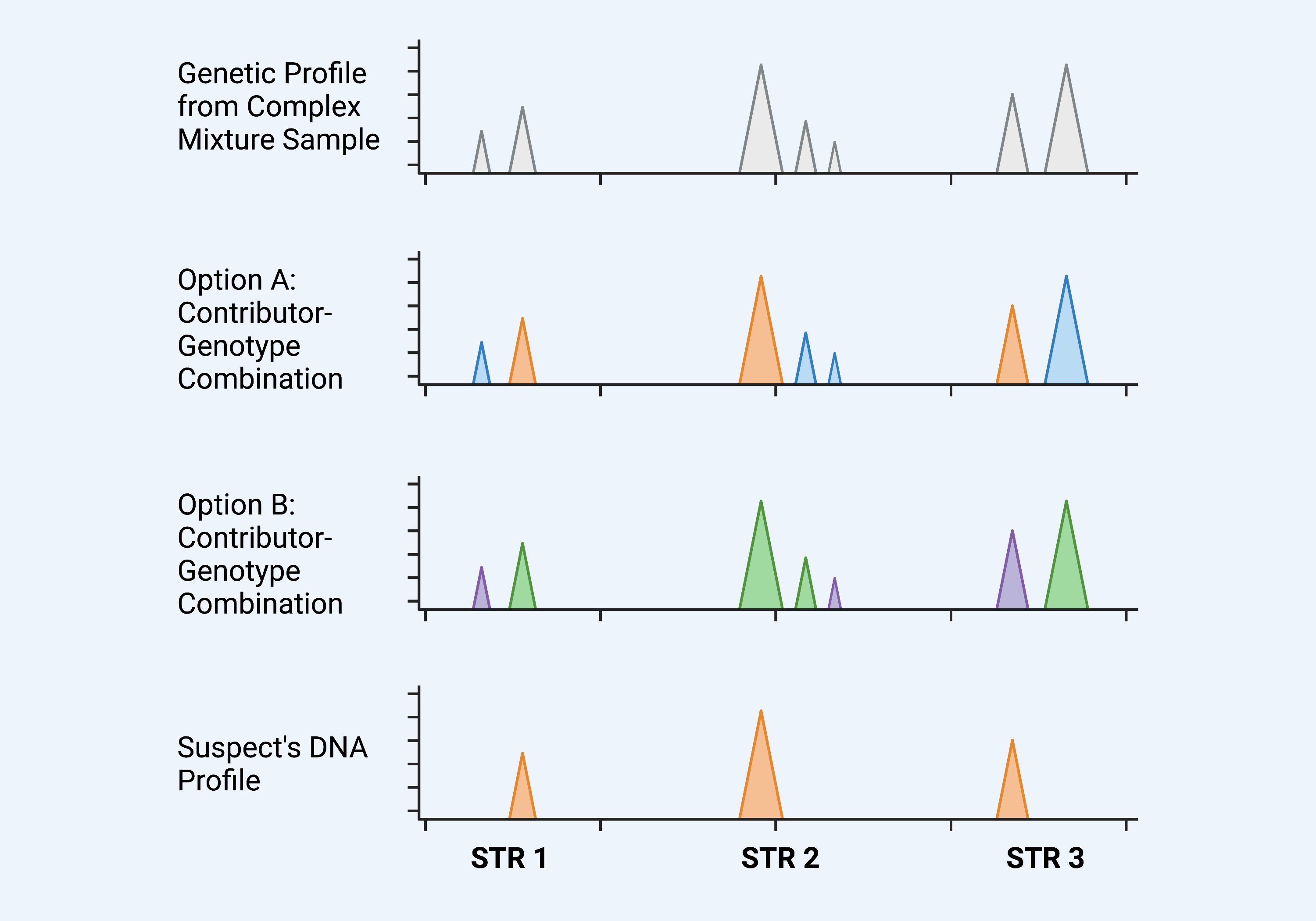
Figure 20. Sensitive forensic DNA collection techniques lead to a greater number of complex mixture samples, which can be explained by multiple different contributor-genotype combinations. The genetic profile from a complex mixture sample (top) may be explained by a number of different contributor-genotype combinations. In Option A, the sample profile can be explained by mixing the suspect’s DNA profile (orange) with another individual’s profile (blue). However, the sample profile can also be explained by a contributor-genotype combination that does not include the suspect, as illustrated in Option B.
Complex DNA mixtures may be taken from mixed blood samples or from surfaces touched by multiple individuals. Interpreting the genetic profiles from complex mixtures (mixture deconvolution) is an incredibly difficult task for laboratory analysts.[2] The appearance or disappearance of allele data at a locus (allele drop-in or drop-out) and poor signal-to-noise ratios can obscure the true number of contributors and their individual DNA profiles. As a result, several automated systems have been developed that promise to objectively analyze and interpret the data. These data, however, have been generally ruled inadmissible in courts.[3]
The most widely adopted methods for interpreting complex DNA mixtures rely on probabilistic genotyping systems (Fig. 21).[4] At their core, many probabilistic genotyping systems use a complex computer algorithm known as a Markov Chain Monte Carlo (MCMC), a type of machine learning, to examine a mixture sample’s DNA profile, simulate possible genotype combinations from different contributors, and evaluate how likely it is that a certain combination of contributors and genotypes could generate a profile matching the forensic sample (Fig. 21).[5]
.png)
Figure 21. Probabilistic Genotyping Systems (PGS) are used to identify potential contributor-genotype combinations in a complex DNA mixture, and assign the likelihood ratio that a person of interest (POI) is a contributor to the mixture.
Probabilistic genotyping systems convey the strength of the evidence that a person of interest (POI) contributed to the forensic mixture using a statistic called a likelihood ratio (Fig. 21). This is a ratio of two competing probabilities:
- The probability of observing the DNA profile if the POI was a contributor to the mixture.
- The probability of observing the DNA profile if the POI was not a contributor to the mixture.
Of course, the value reported in a likelihood ratio is not a probability of innocence or guilt. Instead, likelihood ratios estimate the strength of the evidence that an individual’s DNA is included in a mixture sample.
The two probabilistic genotyping systems most commonly used in the United States are TrueAllele and STRmix.[6] While the exact details differ between the systems, the underlying approach and algorithms are similar.
When evaluating results and evidence generated by probabilistic genotyping systems, there are several technical details to consider. A short summary of these considerations is provided below, and more exhaustive reports can be found in the references.[7]
First, although probabilistic genotyping systems promise an automated and objective method for mixture deconvolution, the contributor-genotype combinations simulated and tested by the system are constrained by the operating analyst who inputs the initial settings. For example, one of these settings is an estimation of the number of contributors to the mixture, thus controlling the possible genotype combinations the system tests. Determining the true number of contributors can be exceptionally difficult for an analyst, especially for the kinds of mixtures that require probabilistic rather than manual interpretation.
The difficulty of determining the number of contributors and assigning the relative fraction of DNA each individual contributed increases as the possible number of contributors increases. Alleles shared among contributors can mask the true number of alleles and their relative abundance (i.e., a four-person mixture could look like a two- or three-person mixture). Inaccurately specifying the number of contributors can affect the results of the analysis.
Second, probabilistic genotyping systems tend to assume that the possible contributors to a mixture are unrelated, and therefore share little similarity in their genetic allele profiles. Genetic relatedness can mask the true number of alleles and their abundance, confounding an analyst's attempts to identify the number of contributors and their relative fraction of DNA. If a case involves multiple individuals with a biological relationship, the computation of the probability of contribution must take that fact into account.
Third, the probabilistic genotyping software will always report a result. This is true regardless of the quality of the DNA sample, the number of contributors to the mixture, or the ability of the algorithm to find a likely contributor-genotype combination. Generally, a profile with limited information will produce a likelihood ratio close to the value of 1.0, which is an indication of uninformative results. For those unfamiliar with likelihood ratios, low values (closer to 0) can give an undue sense of certainty to the analysis.
In some cases, different software can yield contradictory results after analyzing the same sample, as different software is based on different models and assumptions.[8] Even reanalysis of the same sample by the same software using an MCMC process will not necessarily report the exact same likelihood ratio value, since reanalysis involves new simulations that yield slightly different probabilities.
In the absence of a testable “ground truth” for what the output likelihood ratio should be, it is important that the forensic lab analyzing the mixture sample demonstrates extensive and particular validation of the method. The validation should be specific for the quality and complexity of the sample being analyzed, especially since most systems have not been validated for use on mixtures of more than a certain number of contributors even by their developers.
Lastly, there should be scrutiny of the actual simulation software itself. Third-party audits of a commonly used probabilistic genotyping software, the Forensic Statistical Tool (FST) developed by New York City’s DNA Laboratory, identified issues in the source code with meaningful impact for individual cases.[9] Scrutinizing the method and software source code may be difficult when developers argue that the information is proprietary and therefore protected. But application of the trade secret principle has been questioned,[10] and in some cases, like New York City’s FST, judges have granted access to defense attorneys and the public.[11] Now, the FST is no longer used.
[1] U.S. Gov’t Accountability Off. (GAO), Science & Tech Spotlight: Probabilistic Genotyping Software (Sept. 2019), https://www.gao.gov/assets/gao-19-707sp.pdf; Katherine Kwong, The Algorithm Says You Did It: The Use of Black Box Algorithms to Analyze Complex DNA Evidence, 31 Harv. J. L. & Tech. 275 (2017), https://jolt.law.harvard.edu/assets/articlePDFs/v31/31HarvJLTech275.pdf; Rich Press, DNA Mixtures : A Forensic Science Explainer, Nat’l Inst. Standards & Tech. (Apr. 3, 2019), https://www.nist.gov/feature-stories/dna-mixtures-forensic-science-explainer.
[2] Am. Acad. Forensic Sci. Standards Bd., Standard for Validation Studies of DNA Mixtures, and Development and Verification of a Laboratory’s Mixture Interpretation Protocol (2018), https://www.aafs.org/sites/default/files/media/documents/020_Std_e1.pdf.
[3] United States v. Carney, No. 1:20-cr-121, 2022 WL 1155902 (S.D. Ohio Apr. 19, 2022).
[4] Michael D. Coble & Jo-Anne Bright, Probabilistic Genotyping Software: An Overview, 38 Forensic Sci. Int’l: Genetics 219 (2019), available at https://doi.org/10.1016/j.fsigen.2018.11.009; U.S. Gov’t Accountability Off. (GAO), Report to Cong. Requesters, Forensic Technology: Algorithms Used in Federal Law Enforcement (May 2020), https://www.gao.gov/assets/gao-20-479sp.pdf.
[5] Online Workshop Series: Probabilistic Genotyping of Evidentiary DNA Typing Results, Nat’l Inst. Just. Forensic Tech. Ctr. Excellence (2019), https://forensiccoe.org/online-workshop-series-probabilistic-genotyping-of-evidentiary-dna-typing-results/.
[6] Homepage, Cybergenetics, https://www.cybgen.com/ (last visited Feb. 2, 2024); Home, STRmix, https://www.strmix.com/ (last visited Feb. 2, 2024).
[7] Am. Acad. Forensic Sci. Standards Bd., Standard for Validation of Probabilistic Genotyping Systems (2020); President’s Council of Advisors on Sci. & Tech. (PCAST), Forensic Science in Criminal Courts: Ensuring Scientific Validity of Feature-Comparison Methods (Sept. 2016), https://obamawhitehouse.archives.gov/sites/default/files/microsites/ostp/PCAST/pcast_forensic_science_report_final.pdf; Sci. Working Grp. on DNA Analysis Methods (SWGDAM), SWGDAM Guidelines for the Validation of Probabilistic Genotyping Systems (2015), https://www.swgdam.org/_files/ugd/4344b0_22776006b67c4a32a5ffc04fe3b56515.pdf.
[8] William Thompson, Uncertainty in probabilistic genotyping of low template DNA: A case study comparing STRMix™ and TrueAllele™, 68 J. of Forensic Sciences 3, (2023), available at https://doi.org/10.1111/1556-4029.15225.
[9] Lauren Kirchner, Thousands of Criminal Cases in New York Relied on Disputed DNA Testing Techniques, ProPublica & N.Y. Times (September 4, 2017, 6:00 p.m.), https://www.propublica.org/article/thousands-of-criminal-cases-in-new-york-relied-on-disputed-dna-testing-techniques.
[10] Rebecca Wexler, Life, Liberty, and Trade Secrets: Intellectual Property in the Criminal Justice System, 70 Stan. L. Rev. 1343 (2018), available at https://review.law.stanford.edu/wp-content/uploads/sites/3/2018/06/70-Stan.-L.-Rev.-1343.pdf.
[11] Kirchner, supra note 9; Lauren Kirchner, Federal Judge Unseals New York Crime Lab’s Software for Analyzing DNA Evidence, ProPublica (Oct. 20, 2017, 8:00 a.m.), https://www.propublica.org/article/federal-judge-unseals-new-york-crime-labs-software-for-analyzing-dna-evidence.